Written by
doremin
on
on
[얼죽아] 크롤러 1단계
[얼죽아] 크롤러 1단계
-
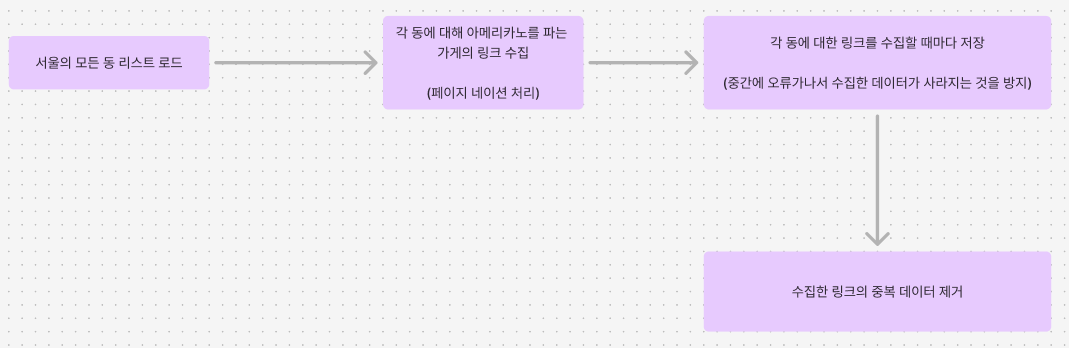
서울의 모든 동에 대해서 아메리카노를 파는 가게를 검색한다. 사용한 지도 서비스는 카카오맵을 이용했다.
-
각 동에 대해서 아메리카노를 파는 가게의 링크를 페이지네이션을 고려하여 수집하였다.
-
각 동에 대해서 링크를 수집할 때마다 csv파일로 저장해주었다. (한번에 저장하려다가 데이터 날려먹음..)
-
수집한 링크에 중복된 데이터가 많을 것이라 중복을 제거해주었다.
고민한 부분
가게의 메뉴를 크롤링 하는 과정을 한번에 진행하지 않고, 2단계로 나누어서 진행한 이유는 다음과 같다.
-
데이터의 중복 가게들을 검색하다보면 중복된 가게들이 검색되어서 저장하는 데이터의 양이 많아진다. 따라서 크롤링 하는 과정을 2단계로 나누어서 1단계에서 가게의 링크를 수집하고, 2단계에서 가게의 메뉴 및 정보를 수집하기로 하였다. 그리고 1단계와 2단계 사이에서 중복을 제거하기로 하였다. 이를 통해서 전체 데이터를 수집하는데 걸리는 시간을 단축시킬 수 있었다.
-
리스크 최소화 프로그램을 에러가 안나게 잘 만들었다면 이런 걱정을 할 필요가 없겠지만, 프로그램 중간에 에러가 난다면 가게의 링크를 수집하는 단계부터 다시 해야한다. 따라서 메뉴를 수집하는 과정과 가게의 링크를 수집하는 과정을 분리해서, 메뉴를 수집하는 과정에서 에러가 발생하더라도, 가게의 링크부터 수집하지 않기 위해서 2단계로 나누었다. 크롤링하는 과정이 시간이 오래 걸리는데 (링크 수집 약 16시간), 이를 통해서 중간에 프로그램에 에러가 발생하더라도 리스크를 최소화 할 수 있었다.