Written by
doremin
on
on
[얼죽아] 데이터 중복제거
[얼죽아] 데이터 중복제거
이전 글에서 크롤링의 1단계와 2단계 사이에 데이터의 중복제거를 한다고 설명했다. 데이터 중복 제거에 사용한 방법을 이 글에서 설명하고자 한다.
알고리즘 선택 과정
전체 수집한 데이터가 20만개 정도고, 이름 한번에 메모리에 로드하고 중복을 제거하면 과도하게 메모리를 사용할 것으로 예상했다. 그래서 external merge sort의 개념을 이용해서 중복 제거를 하기로 하였다.
나중에 알았지만 이 정도 크기의 데이터는 한번에 메모리에 로드해서 처리해도 괜찮을 것 같다. 개별 데이터의 예상 메모리 사용량 100바이트라고 한다면, 100byte * 210,000 = 21,000,000 byte ≈ 21 mb
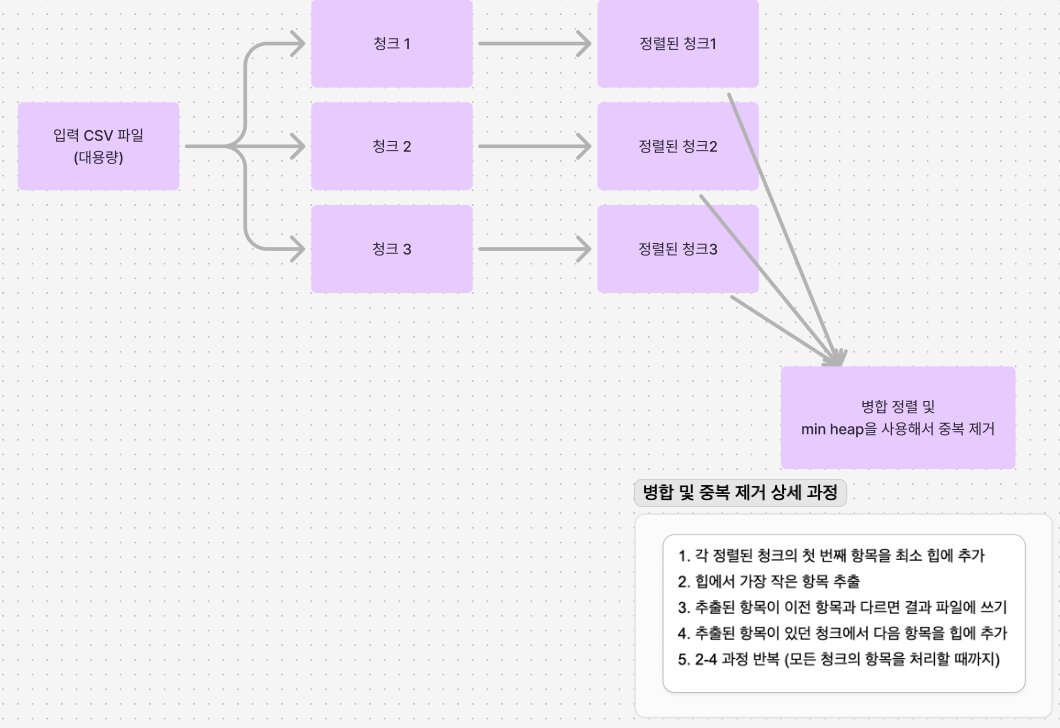
알고리즘 개요
- 입력 파일을 작은 청크로 나눠 읽습니다.
- 각 청크를 메모리 내에서 정렬합니다.
- 정렬된 각 청크를 임시 파일로 저장합니다.
- 모든 임시 파일을 동시에 읽으며 병합 정렬 방식으로 최종 출력 파일을 생성합니다.
- 병합 과정에서 중복을 제거합니다.
Flow Chart
결과
중복 제거하기 전 데이터가 약 216,000개였고, 중복 제거 후에 데이터가 27,609개가 되었다. 서울의 카페 개수가 2024년 2분기 기준 24,444개 출처 이고, 식당에서 아메리카노를 파는 경우를 생각하면 예상했던 26,000 ~ 30,000 사이에 데이터의 개수가 위치한다.
코드 구현
import csv
import os
import tempfile
import heapq
def chunk_sort_and_deduplicate(input_file, output_file, chunk_size=10000):
temp_files = []
# 청크 단위로 읽어서 정렬하고 임시 파일에 저장
with open(input_file, 'r', newline='', encoding='utf-8') as infile:
reader = csv.reader(infile)
header = next(reader) # 헤더 읽기
chunk = []
for i, row in enumerate(reader):
chunk.append(row[0]) # 링크만 저장
if len(chunk) == chunk_size:
chunk.sort()
temp_file = tempfile.NamedTemporaryFile(mode='w+t', delete=False, newline='', encoding='utf-8')
writer = csv.writer(temp_file)
writer.writerows([[link] for link in chunk])
temp_file.close()
temp_files.append(temp_file.name)
chunk = []
if chunk: # 마지막 청크 처리
chunk.sort()
temp_file = tempfile.NamedTemporaryFile(mode='w+t', delete=False, newline='', encoding='utf-8')
writer = csv.writer(temp_file)
writer.writerows([[link] for link in chunk])
temp_file.close()
temp_files.append(temp_file.name)
# 정렬된 임시 파일들을 병합하면서 중복 제거
with open(output_file, 'w', newline='', encoding='utf-8') as outfile:
writer = csv.writer(outfile)
writer.writerow(header) # 헤더 쓰기
files = [open(f, 'r', newline='', encoding='utf-8') for f in temp_files]
readers = [csv.reader(f) for f in files]
heap = []
for i, reader in enumerate(readers):
try:
item = next(reader)[0]
heapq.heappush(heap, (item, i, reader))
except StopIteration:
pass
last_item = None
while heap:
item, i, reader = heapq.heappop(heap)
if item != last_item:
writer.writerow([item])
last_item = item
try:
next_item = next(reader)[0]
heapq.heappush(heap, (next_item, i, reader))
except StopIteration:
pass
# 임시 파일 정리
for f in files:
f.close()
for name in temp_files:
os.unlink(name)
input_file_name = 'results/total_results.csv'
output_file_name = 'results/deduplicated_results.csv'
chunk_sort_and_deduplicate(input_file_name, output_file_name)